同じ言葉なのに「殺される文」と「生き残る文」がある
私たちの体の設計図はDNAに書かれています。
DNAは約30億文字からなる巨大な「レシピ本」のようなもので、そこには約2万種類のタンパク質(体を動かす部品)の作り方が書かれています。
でも、DNAは直接タンパク質を作るわけではありません。
工事現場で例えると、DNAは「金庫に保管された工場全体の設計図」で、各細胞の核に保管された貴重品です。
そんな貴重品を部品を組み立てるごとに引っ張り出すのは、かなりのリスクです。
そこで私たちの細胞は大元の設計図ではなく、一部をコピーした「設計図の部分写し」としてmRNAという分子を使用します。
人間の大工さんなら、この部分写しとにらめっこしながら、木材を切り出し、形を整え、担当する区画を構築していきますが、細胞はもう少しオートマチックです。
設計図の部分写し(mRNA)を部品自動組み立てマシーン(リボソーム)に差し込むだけで、組み立てマシーンが設計図の情報を読み取りつつ、しかも材料であるアミノ酸をどんどん取り込みながら次々に繋げて、タンパク質を作ってくれます。
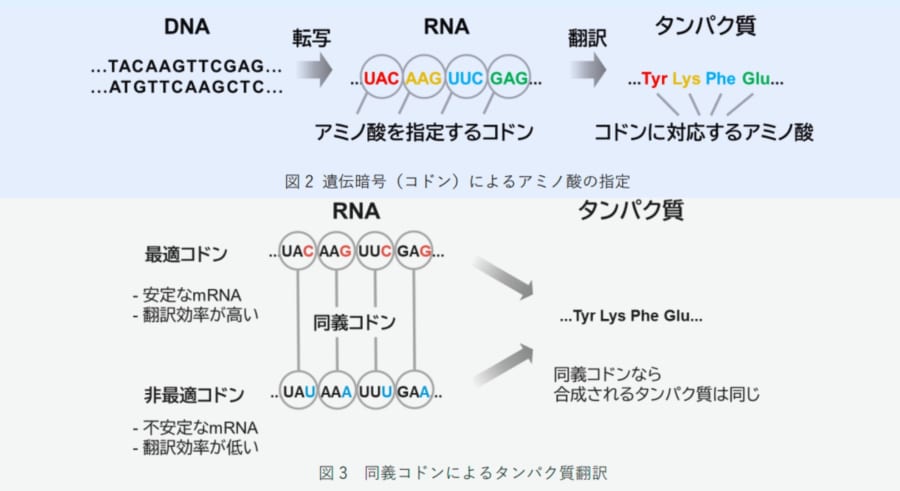
ではどうやって情報を読み取っているかというと、基本にあるのは3文字セットのコードです。
たとえば「GCT」という3文字セットがあればそれは「アラニン」というアミノ酸を指定することになります。
DNAの暗号は4種類の文字が長く長く繋がっていますが、タンパク質の情報が書かれている部分は、基本的にこの3文字セットが延々と続く形で情報が記述されています。
人間の体を作るのに使われているアミノ酸は20種類あります。 「A・T・G・C」の1文字が1つのアミノ酸に対応しているだけなら、4種類のアミノ酸しか使えません。
そこで文字を組み合わせて、複数のアミノ酸を指定できるようにしているわけです。
 「DNAには第2のコード」が存在すると判明――遺伝子を密かに黙らせる隠し指令機構の正体 / Credit: Kyoto University / RIKEN
「DNAには第2のコード」が存在すると判明――遺伝子を密かに黙らせる隠し指令機構の正体 / Credit: Kyoto University / RIKENしかし問題はここからです。
4種類の文字を3つ並べる組み合わせは4×4×4で合計64通りあります。
このうち3つは「ここで翻訳終了」を意味する終止コドンなので、アミノ酸を指定するのに使えるのは61個です。
これで20種類のアミノ酸を指定すればいいので、41個分が「余ってしまう」わけです。
そこで生命はダブりを許可しました。
先ほど「GCT」がアラニンに対応すると言いましたが、実はアラニンを指定するコドンは「GCT」の他に「GCC」「GCA」「GCG」とあわせて4種類も存在しているのです。
英語で「look」「see」「watch」がどれも「見る」というニュアンスになるように、「GCT」「GCC」「GCA」「GCG」はスペルが違ってもどれもアラニンというアミノ酸を持ってこいという指示になるわけです。
生物学者たちはこれを長らく「ただの冗長性(あそび)にすぎない」と考えていました。
教科書でもこう教えます――「どのスペルを使っても、作られるタンパク質は全く同じ」と。
ところが以前から、どれを選ぶかで遺伝子の活発さが大きく変わることが観察されるようになりました。
特にヒトの細胞ではGやCで終わるコドンを使うと遺伝子は活発に働き、AやUで終わるコドンを多用すると、なぜかその遺伝子の部分写し(mRNA)が作られても早々に分解されてしまい、結果としてタンパク質がほとんど作られないのです。
「意味が同じコドンなのに、なぜ結果が違うのか」――これがヒト細胞において長年解けない謎として残っていました。








 English (US) ·
English (US) ·  Japanese (JP) ·
Japanese (JP) ·